TLS termination: stunnel, nginx & stud
Vincent Bernat
Here is the short version: to get better performance on your TLS terminator, use stud on 64-bit system with patch from Émeric Brun for TLS session reuse with some AES cipher suite (128 or 256, does not really matter), without DHE, on as many cores as needed, a key size of 1024 bits unless more is needed.
Update (2011-10)
I received some constructive comments about these tests. After reading this article, I invite you to look at additional benchmarks in the second round.
Update (2015-02)
While the content of this article is still technically sound, ensure you understand it was written by the end of 2011 and therefore doesn’t take into account many important aspects, like the fall of RC4 as an appropriate cipher.
Update (2016-01)
stud is now unmaintained. It has been forked by the Varnish team and is now called hitch. However, I would rather consider HAProxy. It now features TLS support, supplied by one of the major contributor of stud.
Introduction#
One year ago, Adam Langley, from Google, stated TLS was not computationally expensive any more:
In January this year (2010), Gmail switched to using HTTPS for everything by default. Previously it had been introduced as an option, but now all of our users use HTTPS to secure their email between their browsers and Google, all the time. In order to do this we had to deploy no additional machines and no special hardware. On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10 KB of memory per connection and less than 2% of network overhead. Many people believe that SSL takes a lot of CPU time and we hope the above numbers (public for the first time) will help to dispel that.
If you stop reading now you only need to remember one thing: SSL/TLS is not computationally expensive any more.
This is a very informative post containing tips on how to enhance TLS performance by reducing latency. However, unlike Gmail, you may still be worried by TLS raw performances. Maybe each of your frontends is able to serve 2000 requests per second and CPU overhead for TLS is therefore significative. Maybe you want to terminate TLS in your load balancer—even if you know this is not the best way to scale.
Tuning TLS#
There are a lot of knobs you can use to get better performances from TLS: choosing the best implementation, using more CPU cores, switching to 64-bit system, choosing the right cipher suite and the appropriate key size and enabling a session cache.
We will consider three TLS terminators. They all use OpenSSL under
the hood. stunnel is the oldest one and uses a threaded
model. stud is a recent attempt to write a simple TLS
terminator which is efficient and scalable. It uses the
one-process-per-core model. nginx is a web server and it
can be used as reverse proxy and therefore act as TLS terminator. It
is known to be one of the most efficient web server, hence the choice
here. It also features built-in basic load balancing. Since stud and
stunnel1 do not have this feature, we use them with
HAProxy, a high performance load-balancer that usually
defers the TLS part to stunnel (but stud can act as a drop-in
replacement here).
These implementations were already tested by Matt Stancliff. He first concluded nginx sucked at TLS then that nginx did not suck at TLS (in the first case, nginx was the only one to select a DHE cipher suite). The details were very scarce. I hope to bring here more details.
This brings the importance of the selected cipher suite. The client and the server must agree on the cipher suite to use for symmetric encryption. The server will select the strongest one it supports from the list proposed by the client. If you enable some expensive cipher suite on your server, it is likely to be selected.
The last important knob is TLS session reuse. It matters for both performance and latency. During the first handshake, the server will send a session ID. The client can use this session ID to request an abbreviated handshake. This handshake is shorter (latency improvement by one round-trip) and allows us to reuse the previously negotiated master secret (performance improvement by skipping the costliest part of the handshake). See the article from Adam Langley for additional information (with helpful drawings).
The following table shows what cipher suite is selected by some major web sites. I have also indicated whether they support session reuse. See this post from Matt Palmer to know how to check this.
| Site | Cipher | Session reuse? |
|---|---|---|
| www.google.com | RC4-SHA | ✓ |
| www.facebook.com | RC4-MD5 | ✓ |
| twitter.com | AES256-SHA | ✕ |
| windowsupdate.microsoft.com | RC4-MD5 | ✕ |
| www.paypal.com | AES256-SHA | ✕ |
| www.cmcicpaiement.fr | DHE-RSA-AES256-SHA | ✓ |
RFC 5077 defines another mechanism for session resumption that does not require any server-side state. You can find additional information about this optional mechanism in my article about enabling session reuse.
Benchmarks#
All these benchmarks have been run on a HP DL 380 G7, with two Xeon
L5630 (running at 2.13GHz for a total of 8 cores), without
hyperthreading, using a 2.6.39 kernel (HZ is set to 250) and two
Intel 82576 NIC. Linux conntrack subsystem has been disabled and file
limits have been raised over 100,000.
A Spirent Avalanche 2900 appliance is used to run the benchmarks.
We are interested in raw TLS performances in term of handshakes per second. Because we want to observe the effects of session reuse, the scenario runs by most tests lets clients doing four successive requests and reusing the TLS session for three of them. There is no HTTP keepalive. There is no compression. The size of the HTTP answer from the server is 1024 bytes. These choices are done because our primary target is the number of TLS handshakes per second.
It should also be noted that HAProxy alone is able to handle 22,000 TPS on one core. During the tests, it was never the bottleneck.
Implementation#
We run a first bench to compare nginx, stud and stunnel on one core. This bench runs on a 32-bit system, with AES128-SHA1 cipher suite and a 1024-bit key size. Here is the result for stud (version 0.1, with Émeric Brun’s patch for TLS session reuse):
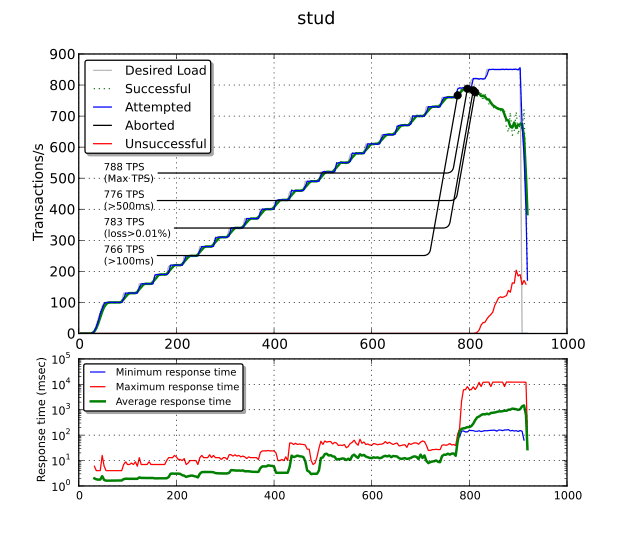
The most important plot is the top one. The blue line is the attempted number of transactions per second (TPS) while the green one is the successful number of TPS. When the two lines start to diverge, this means we reach some kind of maximum: the number of unsuccessful TPS also starts to raise (the red line).
There are several noticeable points: the maximum TPS (788 TPS), the maximum TPS with an average response time less than 100 ms (766 TPS), less than 500 ms (776 TPS) and the maximum TPS with less than 0.01% of packet loss (783 TPS).
Let’s have a look at nginx (version 1.0.5):
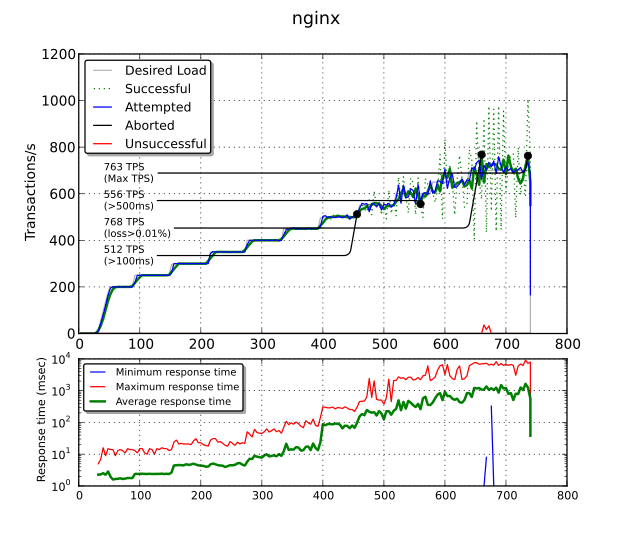
It is able to get the same performance as stud (763 TPS). However,
over 512 TPS, you get more than 100 ms of response time. Over 556 TPS,
you even get more than 500 ms! I get this behavior in every bench
with nginx (with or without proxy_buffering, with or without
tcp_nopush, with or without tcp_nodelay) and I am unable to
explain it. Maybe there is
something wrong in the configuration. After hitting this
limit, nginx starts to process connections by bursts. Therefore, the
number of successful TPS is plotted using a dotted line while the
moving average over 20 seconds is plotted with a solid line.
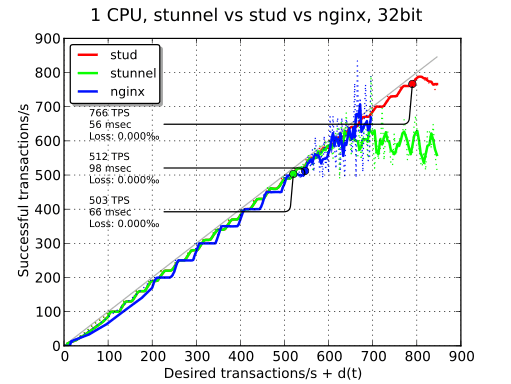
On the next plot, you can see the compared performance of the three implementations. On this kind of plot, the number of TPS that we keep is the maximum number of TPS where loss is less than 0.1% and average response time is less than 100 ms. stud achieves a performance of 766 TPS while nginx and stunnel are just above 500 TPS.
Number of cores#
With multiple cores, we can affect several of them to do TLS hard work. To get better performance, we pin each processes to a dedicated CPU. Here is the repartition used during the tests:
| 1 core | 2 cores | 4 cores | 6 cores | |
|---|---|---|---|---|
| CPU 1, Core 1 | network | network | network | network + haproxy |
| CPU 1, Core 2 | haproxy | haproxy | haproxy | TLS |
| CPU 1, Core 3 | TLS | TLS | TLS | TLS |
| CPU 1, Core 4 | - | TLS | TLS | TLS |
| CPU 2, Core 5 | - | - | network | TLS |
| CPU 2, Core 6 | - | - | TLS | TLS |
| CPU 2, Core 7 | - | - | TLS | TLS |
| CPU 2, Core 8 | system | system | system | system + haproxy |
Remember, we have two CPU, 4 cores on each CPU. Cores on the same CPU
share the same L2 cache (on this model). Therefore, the arrangement
inside a CPU is not really important. When possible, we try to keep
things together on the same CPU. The TLS processes always get
exclusive use of a core since they will always be the most busy. The
repartition is done with cpuset(7) for userland processes
and by setting smp_affinity for network card interrupts.
We keep one core for the system. It is quite important to be able to connect and monitor the system correctly even when it is loaded. With so many cores, we can afford to reserve one core for this usage.
Beware! There is a trap when pining processes or IRQ to a core. You
need to check /proc/cpuinfo to discover the mapping between kernel
processors and physical cores. Sometimes, second kernel processor can
be the first core of the second physical processor (instead of the
second core of the first physical processor).
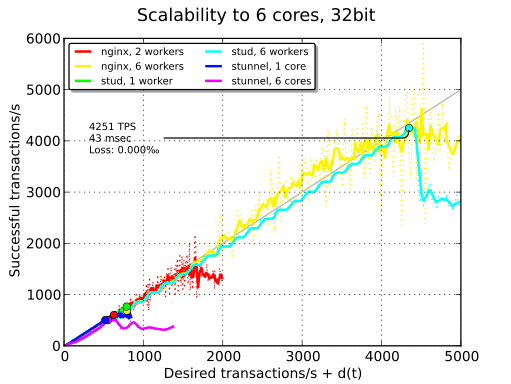
As you can see in the plot above, only stud is able to scale properly. stunnel is not able to take advantage of the cores and its performance is worse than with a single core. I think this may be due to its threaded model and the fact that the userland for this 32-bit system is a bit old. nginx is able to achieve the same TPS than stud but is disqualified because of the increased latency. We won’t use stunnel in the remaining tests.
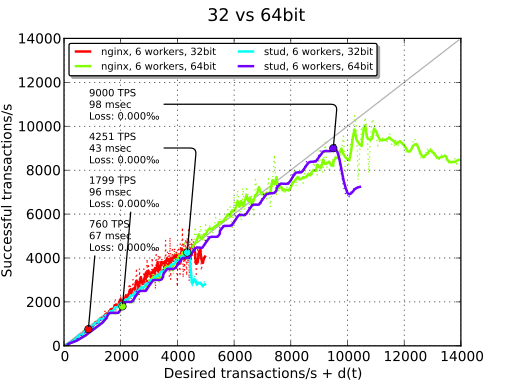
32-bit vs 64-bit#
The easiest way to achieve a performance boost is to switch to a 64-bit system. TPS are doubled. On our 64-bit system, thanks to the use of a version of OpenSSL with the appropriate support, AES-NI, a CPU extension to improve the speed of AES encryption/decryption, is enabled. Remaining tests are done with a 64-bit system.
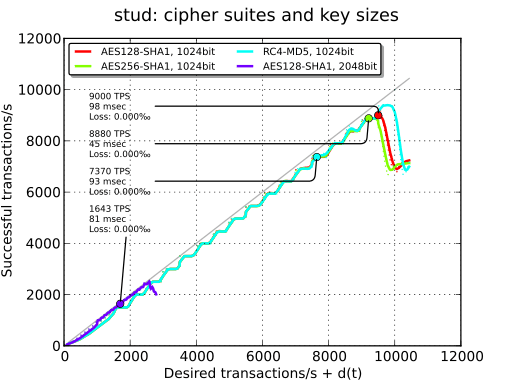
Ciphers and key sizes#
In our tests, the influence of ciphers is minimal. There is almost no difference between AES256 and AES128. Using RC4 adds some latency. The use of AES-NI may have helped to avoid this latency for AES.
On the other hand, using a 2048-bit key size has a huge performance hit. TPS are divided by 5.
Session cache#
The last thing to check is the influence of TLS session reuse. Since we are on a local network, we see only one of the positive effects of session reuse: better TPS because of reduced CPU usages. If there was a latency penalty, we should also have seen better TPS thanks to the removed round-trip.
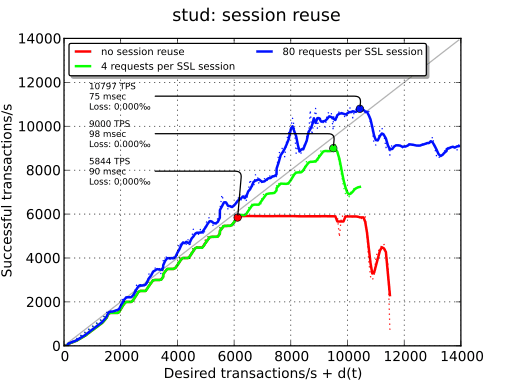
This plot also explains why stud performance fall after the maximum: because of the failed transactions, the session cache is not as efficient. This phenomenon does not exist when session reuse is not enabled.
Conclusion#
Here is a summary of the maximum TPS reached during the benchmark (with an average response time below 100ms). Our control use case is the following: 64-bit, 6 cores, AES128, SHA1, 1024-bit key, 4 requests into the same TLS session.
| Context | nginx 1.0.5 | stunnel 4.41 | stud 0.1 (patched) |
|---|---|---|---|
| 1 core, 32-bit | 512 TPS | 503 TPS | 766 TPS |
| 2 cores, 32-bit | 599 TPS | - | - |
| 32-bit | 804 TPS | 501 TPS | 4251 TPS |
| - | 1799 TPS | - | 9000 TPS |
| AES256 | - | - | 8880 TPS |
| RC4-MD5 | - | - | 7370 TPS |
| 2048-bit | - | - | 1643 TPS |
| no session reuse | - | - | 5844 TPS |
| 80 requests per TLS session | - | - | 10797 TPS |
Therefore, stud in our control scenario is able to sustain 1500 TPS per core. It seems to be the best current option for a TLS termination. It is not available in Debian yet, but I intend to package it.
Here is how stud is invoked:
# ulimit -n 100000 # stud -n 2 -f 172.31.200.15,443 -b 127.0.0.1,80 -c ALL \ > -B 1000 -C 20000 --write-proxy \ > =(cat server1024.crt server1024.key dhe1024)
You may also want to look at HAProxy configuration, nginx configuration and stunnel configuration.
Update (2011-10)
More benchmarks are available in the second part. Keep reading!
-
In fact, stunnel also has simple round-robin load balancing by specifying
connectmultiple times in the configuration. ↩︎