lldpd 0.7.1
Vincent Bernat
A few weeks ago, a new version of lldpd, a 802.1AB (aka LLDP) implementation for various Unices, has been released.
LLDP is an industry standard protocol designed to supplant proprietary Link-Layer protocols such as EDP or CDP. The goal of LLDP is to provide an inter-vendor compatible mechanism to deliver Link-Layer notifications to adjacent network devices.
In short, LLDP allows you to know exactly on which port is a server (and reciprocally). To illustrate its use, I have made a xkcd-like strip:
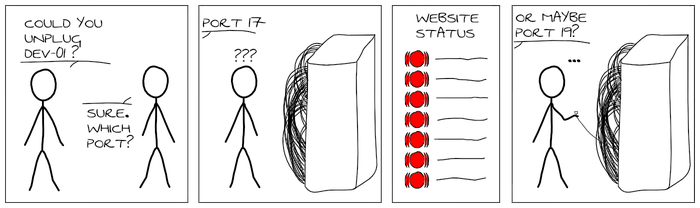
If you would like more information about lldpd, please have a look at its new dedicated website. This blog post is an insight of various technical changes that have affected lldpd since its latest major release one year ago. Lots of C stuff ahead!
Version & changelog#
Update (2013-02)
Guillem Jover told me how he met the same
goals for libbsd. First, save the version from git into
.dist-version and use this file if it exists. This allows one to
rebuild ./configure from the published tarball without losing the
version. This also handles Thorsten Glaser’s critic. Then,
include CHANGELOG in DISTCLEANFILES variable. Since this is a
better solution, I have adopted the appropriate lines of code from
libbsd. The two following sections are partly technically outdated.
Automated version#
In configure.ac, I was previously using a static version number that
I had to increase when releasing:
AC_INIT([lldpd], [0.5.7], [bernat@luffy.cx])
Since the information is present in the git tree, this seems a bit redundant (and easy to forget). Taking the version from the git tree is easy:
AC_INIT([lldpd],
[m4_esyscmd_s([git describe --tags --always --match [0-9]* 2> /dev/null || date +%F])],
[bernat@luffy.cx])
If the head of the git tree is tagged, you get the exact tag (0.7.1
for example). If it is not, you get the nearest one, the number of
commits since it and part of the current hash (0.7.1-29-g2909519 for
example).
The drawback of this approach is that if you rebuild configure
from the released tarball, you don’t have the git tree and the version
will be a date. Don’t do that.
Automated changelog#
Generating the changelog from git is a common practice. I had some
difficulties to make it right. Here is my attempt (I am using
automake):
dist_doc_DATA = README.md NEWS ChangeLog .PHONY: $(distdir)/ChangeLog dist-hook: $(distdir)/ChangeLog $(distdir)/ChangeLog: $(AM_V_GEN)if test -d $(top_srcdir)/.git; then \ prev=$$(git describe --tags --always --match [0-9]* 2> /dev/null) ; \ for tag in $$(git tag | grep -E '^[0-9]+(\.[0-9]+){1,}$$' | sort -rn); do \ if [ x"$$prev" = x ]; then prev=$$tag ; fi ; \ if [ x"$$prev" = x"$$tag" ]; then continue; fi ; \ echo "$$prev [$$(git log $$prev -1 --pretty=format:'%ai')]:" ; \ echo "" ; \ git log --pretty=' - [%h] %s (%an)' $$tag..$$prev ; \ echo "" ; \ prev=$$tag ; \ done > $@ ; \ else \ touch $@ ; \ fi ChangeLog: touch $@
Changelog entries are grouped by version. Since it is a bit verbose, I
still maintain a NEWS file with important changes.
Core#
C99#
I have recently read 21st Century C which has some good bits and also handles the ecosystem around C. I have definitively adopted designated initializers in my coding style. Being a GCC extension since a long time, this is not a major compatibility problem.
Without designated initializers:
struct netlink_req req; struct iovec iov; struct sockaddr_nl peer; struct msghdr rtnl_msg; memset(&req, 0, sizeof(req)); memset(&iov, 0, sizeof(iov)); memset(&peer, 0, sizeof(peer)); memset(&rtnl_msg, 0, sizeof(rtnl_msg)); req.hdr.nlmsg_len = NLMSG_LENGTH(sizeof(struct rtgenmsg)); req.hdr.nlmsg_type = RTM_GETLINK; req.hdr.nlmsg_flags = NLM_F_REQUEST | NLM_F_DUMP; req.hdr.nlmsg_seq = 1; req.hdr.nlmsg_pid = getpid(); req.gen.rtgen_family = AF_PACKET; iov.iov_base = &req; iov.iov_len = req.hdr.nlmsg_len; peer.nl_family = AF_NETLINK; rtnl_msg.msg_iov = &iov; rtnl_msg.msg_iovlen = 1; rtnl_msg.msg_name = &peer; rtnl_msg.msg_namelen = sizeof(struct sockaddr_nl);
With designated initializers:
struct netlink_req req = { .hdr = { .nlmsg_len = NLMSG_LENGTH(sizeof(struct rtgenmsg)), .nlmsg_type = RTM_GETLINK, .nlmsg_flags = NLM_F_REQUEST | NLM_F_DUMP, .nlmsg_seq = 1, .nlmsg_pid = getpid() }, .gen = { .rtgen_family = AF_PACKET } }; struct iovec iov = { .iov_base = &req, .iov_len = req.hdr.nlmsg_len }; struct sockaddr_nl peer = { .nl_family = AF_NETLINK }; struct msghdr rtnl_msg = { .msg_iov = &iov, .msg_iovlen = 1, .msg_name = &peer, .msg_namelen = sizeof(struct sockaddr_nl) };
Logging#
Logging in lldpd was not extensive. Usually, when receiving a bug
report, I asked the reporter to add some additional printf() calls
to determine where the problem was. This was suboptimal. Therefore, I
have added many log_debug() calls with the ability to filter out
some of them. For example, to debug interface discovery, one can run
lldpd with lldpd -ddd -D interface.
Moreover, I have added colors when logging to a terminal. This may seem pointless but it is now far easier to spot warning messages from debug ones.
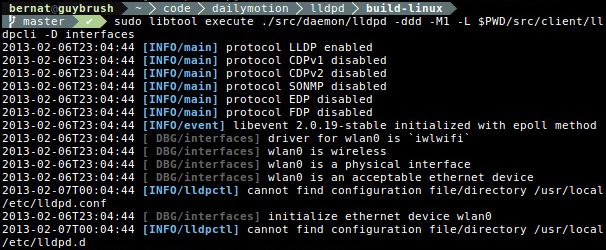
libevent#
In lldpd 0.5.7, I was using my own select()-based event loop. It
worked but I didn’t want to grow a full-featured event loop inside
lldpd. Therefore, I switched to libevent.
The minimal required version of libevent is 2.0.5. A convenient way to check the changes in API is to use Upstream Tracker, a website tracking API and ABI changes for various libraries. This version of libevent is not available in many stable distributions. For example, Debian Squeeze or Ubuntu Lucid only have 1.4.13. I am also trying to keep compatibility with very old distributions, like RHEL 2, which does not have a packaged libevent at all.
For some users, it may be a burden to compile additional libraries. Therefore, I have included libevent source code in lldpd source tree (as a git submodule) and I am only using it if no suitable system libevent is available.
Have a look at m4/libevent.m4 and
src/daemon/Makefile.am to see how this is
done.
Client#
Serialization#
lldpctl is a client querying lldpd to display discovered
neighbors. The communication is done through a Unix socket. Each
structure to be serialized over this socket should be described with a
string. For example:
#define STRUCT_LLDPD_DOT3_MACPHY "(bbww)" struct lldpd_dot3_macphy { u_int8_t autoneg_support; u_int8_t autoneg_enabled; u_int16_t autoneg_advertised; u_int16_t mau_type; };
I did not want to use stuff like Protocol Buffers because I didn’t want to copy the existing structures to other structures before serialization (and the other way after deserialization).
However, the serializer in lldpd did not allow one to handle reference to other structures, lists or circular references. I have written another one which works by annotating a structure with some macros:
struct lldpd_chassis { TAILQ_ENTRY(lldpd_chassis) c_entries; u_int16_t c_index; u_int8_t c_protocol; u_int8_t c_id_subtype; char *c_id; int c_id_len; char *c_name; char *c_descr; u_int16_t c_cap_available; u_int16_t c_cap_enabled; u_int16_t c_ttl; TAILQ_HEAD(, lldpd_mgmt) c_mgmt; }; MARSHAL_BEGIN(lldpd_chassis) MARSHAL_TQE (lldpd_chassis, c_entries) MARSHAL_FSTR (lldpd_chassis, c_id, c_id_len) MARSHAL_STR (lldpd_chassis, c_name) MARSHAL_STR (lldpd_chassis, c_descr) MARSHAL_SUBTQ(lldpd_chassis, lldpd_mgmt, c_mgmt) MARSHAL_END;
Only pointers need to be annotated. The remaining of the structure can
be serialized with just memcpy().1 I think there is still
room for improvement. It should be possible to add annotations inside
the structure and avoid some duplication. Or maybe, using a
C parser? Or using the AST output from LLVM?
Library#
In lldpd 0.5.7, there are two possible entry points to interact with the daemon:
- Through SNMP support. Only information available in LLDP-MIB are exported. Therefore, implementation-specific values are not available. Moreover, SNMP support is currently read-only.
- Through
lldpctl. Thanks to a contribution from Andreas Hofmeister, the output can be requested to be formatted as an XML document.
Integration of lldpd into a network stack was therefore limited to one of these two channels. As an example, you can have a look at how Vyatta made the integration using the second solution.
To provide a more robust solution, I have added a shared library,
liblldpctl, with a stable and well-defined API. lldpctl is now
using it. I have followed these directions:2
- Consistent naming (all exported symbols are prefixed by
lldpctl_). No pollution of the global namespace. - Consistent return codes (on errors, all functions returning
pointers are returning
NULL, all functions returning integers are returning-1). - Reentrant and thread-safe. No global variables.
- One well-documented include file.
- Reduce the use of boilerplate code. Don’t segfault on
NULL, accept integer input as string, provide easy iterators, … - Asynchronous API for input/output. The library delegates reading and writing by calling user-provided functions. These functions can yield their effects. In this case, the user has to callback the library when data is available for reading or writing. It is therefore possible to integrate the library with any existing event-loop. A thin synchronous layer is provided on top of this API.
- Opaque types with accessor functions.
Accessing bits of information is done through “atoms” which are opaque
containers of type lldpctl_atom_t. From an atom, you can extract
some properties as integers, strings, buffers or other atoms. The list
of ports is an atom. A port in this list is also an atom. The list of
VLAN present on this port is an atom, as well as each VLAN in this
list. The VLAN name is a NULL-terminated string living in the scope
of an atom. Accessing a property is done by a handful of functions,
like lldpctl_atom_get_str(), using a specific key. For example, here
is how to display the list of VLAN assuming you have one port as an
atom:
vlans = lldpctl_atom_get(port, lldpctl_k_port_vlans); lldpctl_atom_foreach(vlans, vlan) { vid = lldpctl_atom_get_int(vlan, lldpctl_k_vlan_id)); name = lldpctl_atom_get_str(vlan, lldpctl_k_vlan_name)); if (vid && name) printf("VLAN %d: %s\n", vid, name); } lldpctl_atom_dec_ref(vlans);
Internally, an atom is typed and reference counted. The size of the
API is greatly limited thanks to this concept. There are currently
more than one hundred pieces of information that can be retrieved from
lldpd.
Ultimately, the library will also enable the full configuration of
lldpd. Currently, many aspects can only be configured through
command-line flags. The use of the library does not replace
lldpctl which will still be available and be the primary client of
the library.
CLI#
Having a configuration file was requested since a long time. I didn’t
want to include a parser in lldpd: I am trying to keep it small. It
was already possible to configure lldpd through
lldpctl. Locations, network policies and power policies were the
three items that could be configured this way. So, the next step was
to enable lldpctl to read a configuration file, parse it and send
the result to lldpd. As a bonus, why not provide a full CLI
accepting the same statements with inline help and completion?
Parsing & completion#
Because of completion, it is difficult to use a YACC generated parser. Instead, I define a tree where each node accepts a word. A node is defined with this function:
struct cmd_node *commands_new( struct cmd_node *, const char *, const char *, int(*validate)(struct cmd_env*, void *), int(*execute)(struct lldpctl_conn_t*, struct writer*, struct cmd_env*, void *), void *);
A node is defined by:
- its parent;
- an optional accepted static token;
- a help string;
- an optional validation function; and
- an optional function to execute if the current token is accepted.
When walking the tree, we maintain an environment which is both a
key-value store and a stack of positions in the tree. The validation
function can check the environment to see if we are in the right
context (we want to accept the keyword foo only once, for
example). The execution function can add the current token as a value
in the environment but it can also pop the current position in the
tree to resume walk from a previous node.
As an example, see how nodes for configuration of a coordinate-based location are registered:
/* Our root node */ struct cmd_node *configure_medloc_coord = commands_new( configure_medlocation, "coordinate", "MED location coordinate configuration", NULL, NULL, NULL); /* The exit node. The validate function will check if we have both latitude and longitude. */ commands_new(configure_medloc_coord, NEWLINE, "Configure MED location coordinates", cmd_check_env, cmd_medlocation_coordinate, "latitude,longitude"); /* Store latitude. Once stored, we pop two positions to go back to the "root" node. The user can only enter latitude once. */ commands_new( commands_new( configure_medloc_coord, "latitude", "Specify latitude", cmd_check_no_env, NULL, "latitude"), NULL, "Latitude as xx.yyyyN or xx.yyyyS", NULL, cmd_store_env_value_and_pop2, "latitude"); /* Same thing for longitude */ commands_new( commands_new( configure_medloc_coord, "longitude", "Specify longitude", cmd_check_no_env, NULL, "longitude"), NULL, "Longitude as xx.yyyyE or xx.yyyyW", NULL, cmd_store_env_value_and_pop2, "longitude");
The definition of all commands is still a bit verbose but the system is simple enough yet powerful enough to cover all needed cases.
Readline#
When faced with a CLI, we usually expect some perks like completion, history handling and help. The most used library to provide such features is the GNU Readline Library. Because this is a GPL library, I have first searched an alternative. There are several of them:
- NetBSD Editline library (
libedit). - Autotool port of the NetBSD Editline library (also
libedit). - Debian version of the Editline library (
libeditline). - linenoise, a small and minimal readline library.
- Many others.
From an API point of view, the first three libraries support the GNU Readline API. They also have a common native API. Moreover, this native API also handles tokenization. Therefore, I have developed the first version of the CLI with this API.3
Unfortunately, I noticed later this library is not very common in the Linux world and is not available in RHEL. Since I have used the native API, it was not possible to fallback to the GNU Readline library. So, let’s switch! Thanks to the appropriate macro from the Autoconf Archive (with small modifications), the compilation and linking differences between the libraries are taken care of.
Because GNU Readline library does not come with a tokenizer, I had to write one myself. The API is also badly documented and it is difficult to know which symbol is available in which version. I have limited myself to:
readline(),addhistory();rl_insert_text();rl_forced_update_display();rl_bind_key();rl_line_buffer, andrl_point.
Unfortunately, the various libedit libraries have a noop for
rl_bind_key(). Therefore, completion and online help is not
available with them. I have noticed that most BSD come with GNU
Readline library preinstalled, so it could be considered as a system
library. Nonetheless, linking with libedit to avoid licensing issues
is possible and help can be obtained by prefixing the command with
help.
OS specific support#
Netlink on Linux#
Previously, the list of interfaces was retrieved through
getifaddrs(). lldpd is now using directly Netlink on
Linux. This is not a big change since the GNU C Library already uses
it to implement getifaddrs() and additional information, like VLAN,
are still retrieved through ioctl() or sysfs. However, lldpd
now gets notified when a change happens and update all interfaces in
the next second.
Like many other projects, I have written my own Netlink implementation instead of using libnl, a nice collection of libraries providing everything you need to query the kernel through Netlink, including some advanced bits. Why?
-
The latest version of libnl is still young and its availability in major distributions is scarce. It is not available in Debian Squeeze but will be available in Debian Wheezy. Like libevent, I could circumvent this problem by shipping the library with lldpd and use it when there is not system alternative. But…
-
libnl is licensed under LGPL 2.1. This makes static linking difficult because the license is quite shaddy about static linking being derivative work or not. It is believed that it is authorized under the same provisions as in LGPL 3 which handles the case explicitly. This has been a problem with many projects. For example, OGRE has added an exception for static linking in version 1.6 and switched to MIT license in version 1.7.
I had a short discussion with Thomas Graf about this issue and he seems willing to add a similar exception. This may take some time, but once this is done, I will happily switch to libnl and retrieve more stuff from Netlink.4
BSD support#
Until version 0.7, lldpd was Linux-only. The rewrite to use Netlink was the occasion to abstract interfaces and to port to other OS. The first port was for Debian GNU/kFreeBSD, then for FreeBSD, OpenBSD and NetBSD. They all share the same source code:
getifaddrs()to get the list of interfaces;bpf(4)to attach to an interface to receive and send packets; andPF_ROUTEsocket to be notified when a change happens.
Each BSD has its own ioctl() to retrieve VLAN, bridging and bonding
bits but they are quite similar. The code was usually adapted from
ifconfig.c.
The BSD ports have the same functionalities than the Linux port, except for NetBSD which lacks support for LLDP-MED inventory since I didn’t find a simple way to retrieve DMI related information.
They also offer greater security by filtering packets sent. Moreover, OpenBSD allows one to lock the filters set on the socket:
/* Install write filter (optional) */ if (ioctl(fd, BIOCSETWF, (caddr_t)&fprog) < 0) { rc = errno; log_info("privsep", "unable to setup write BPF filter for %s", name); goto end; } /* Lock interface */ if (ioctl(fd, BIOCLOCK, (caddr_t)&enable) < 0) { rc = errno; log_info("privsep", "unable to lock BPF interface %s", name); goto end; }
This is a very nice feature. lldpd is using a privileged process to open the raw socket. The socket is then transmitted to an unprivileged process. Without this feature, the unprivileged process can remove the BPF filters. I have ported the ability to lock a socket filter program to Linux. However, I still have to add a write filter.
macOS support#
Once FreeBSD was supported, supporting macOS seemed easy. I got sponsored by xcloud.me which provided a virtual Mac server. Making lldpd work with macOS took only two days, including a full hour to guess how to get Apple Xcode without providing a credit card.
To help people installing lldpd on macOS, I have also written a lldpd formula for Homebrew which seems to be the most popular package manager for macOS.
Upstart and systemd support#
Many distributions propose Upstart and systemd as a replacement or an alternative for the classic SysV init. Like most daemons, lldpd detaches itself from the terminal and run in the background, by forking twice, once it is ready (for lldpd, this just means we have setup the control socket). While both Upstart and systemd can accommodate daemons that behave like this, it is recommended to not fork. How to advertise readiness in this case?
With Upstart, lldpd will send itself the SIGSTOP
signal. Upstart will detect this, resume lldpd with SIGCONT and
assume it is ready. The code to support Upstart is therefore quite
simple. Instead of calling daemon(), do this:
const char *upstartjob = getenv("UPSTART_JOB"); if (!(upstartjob && !strcmp(upstartjob, "lldpd"))) return 0; log_debug("main", "running with upstart, don't fork but stop"); raise(SIGSTOP);
The job configuration file looks like this:
# lldpd - LLDP daemon description "LLDP daemon" start on net-device-up IFACE=lo stop on runlevel [06] expect stop respawn script . /etc/default/lldpd exec lldpd $DAEMON_ARGS end script
Update (2019-05)
Current versions do not rely on this signalling system any more, because of a bug in Upstart.
systemd provides a socket to achieve the same goal. An application
is expected to write READY=1 to the socket when it is ready. With
the provided library, this is just a matter of calling
sd_notify("READY=1\n"). Since sd_notify() has less than 30 lines
of code, I have rewritten it to avoid an external dependency. The
appropriate unit file is:
[Unit] Description=LLDP daemon Documentation=man:lldpd(8) [Service] Type=notify NotifyAccess=main EnvironmentFile=-/etc/default/lldpd ExecStart=/usr/sbin/lldpd $DAEMON_ARGS Restart=on-failure [Install] WantedBy=multi-user.target
OS include files#
Linux-specific include files were a major pain in previous versions of
lldpd. The problems range from missing header files (like
linux/if_bonding.h) to the use of kernel-only types. These headers
have a difficult history. They were first shipped with the C library
but were rarely synced and almost always outdated. They were then
extracted from kernel version with almost no change and lagged behind
the kernel version used by the released distribution.5
Today, the problem is acknowledged and is being solved by both the distributions which extract the headers from the packaged kernel and by kernel developers with a separation of kernel-only headers from user-space API headers. However, we still need to handle legacy.
A good case is linux/ethtool.h:
- It can just be absent.
- It can use
u8,u16types which are kernel-only types. To work around this issue, type munging can be setup. - It can miss some definition, like
SPEED_10000. In this case, you either define the missing bits and find yourself with a long copy of the original header interleaved with#ifdefor conditionally use each symbol. The latter solution is a burden by itself but it also hinders some functionalities that can be available in the running kernel.
The easy solution to all this mess is to just include the appropriate kernel headers into the source tree of the project. Thanks to Google ripping them for its Bionic C library, we know that copying kernel headers into a program does not create a derivative work.
-
Therefore, the use of
u_int16_tandu_int8_ttypes is a left-over of the previous serializer where the size of all members was important. ↩︎ -
For more comprehensive guidelines, be sure to check Writing a C library. Also have a look at Sean Barret’s guidelines or Chris Wellons’s ones to get a more complete picture. ↩︎
-
Tokenization is not the only advantage of
libeditnative API. The API is also cleaner, does not have a global state and has a better documentation. All the implementations are also BSD licensed. ↩︎ -
A few years later, as some contributors were opposed to an exception or license change, the situation has not changed. ↩︎
-
For example, in Debian Sarge, the Linux kernel was a 2.6.8 (2004) while the kernel headers were extracted from some pre-2.6 kernel. ↩︎